Original post is here: eklausmeier.goip.de
Another theme for Simplified Saaze called "Wendt". You can inspect it here.
It offers below features:
- Responsive with media breaks for large and small screens, and for printing.
- Top menu with submenus.
- Two column using CSS grid, "Holy Grail Layout".
- Multiple blogs:
- Each category has its own blog by using filtering.
- Each author has its own blog by using filtering.
- Aggregate blog, i.e., the combination of the above.
- Using the
<!--more-->tag to showcase the initial content of a blog post. - Sitemap in HTML and XML, RSS feed.
- WebAssembly based search using pagefind.
- No cookies, therefore no annoying cookie banner required.
The theme looks like this:
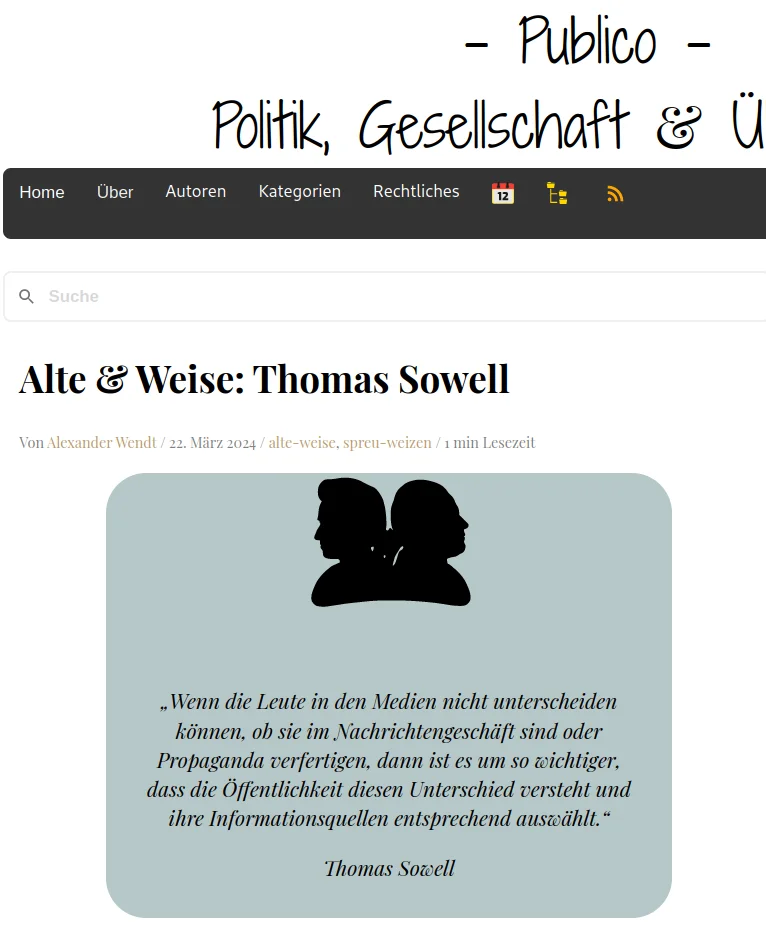
This theme is modeled after the blog from Alexander Wendt. That blog is powered by WordPress and hosted on Cloudflare. I have written on this PublicoMag website: Performance Remarks on PublicoMag Website. Alexander Wendt started this blog in October 2017. The number of posts per year are given in below table. Year 2024 is not complete. As time passes the year 2024 will have more and more posts.
| Year | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 |
|---|---|---|---|---|---|---|---|---|
| #posts | 50 | 237 | 191 | 190 | 179 | 177 | 168 | 43 |
| #comments | 721 | 3999 | 3211 | 2973 | 2480 | 1300 | 1115 | 230 |
Number of comments were counted like this (varying 2017 to 2024):
1perl -ne 'if (/^(\d+) Kommentare <\/h5>/) { $s+=$1; printf("%d\t%d\t%s\n",$1,$s,$ARGV); }' 2017*
1. Installation #
There are two parts in the installation.
1. Install the theme including content and the Simplified Saaze static site generator using composer:
1$ composer create-project eklausme/saaze-wendt
2Creating a "eklausme/saaze-wendt" project at "./saaze-wendt"
3Installing eklausme/saaze-wendt (v1.0)
4 - Downloading eklausme/saaze-wendt (v1.0)
5 - Installing eklausme/saaze-wendt (v1.0): Extracting archive
6Created project in /tmp/T/saaze-wendt
7Loading composer repositories with package information
8Updating dependencies
9Lock file operations: 1 install, 0 updates, 0 removals
10 - Locking eklausme/saaze (v2.2)
11Writing lock file
12Installing dependencies from lock file (including require-dev)
13Package operations: 1 install, 0 updates, 0 removals
14 - Downloading eklausme/saaze (v2.2)
15 - Installing eklausme/saaze (v2.2): Extracting archive
16Generating optimized autoload files
17No security vulnerability advisories found.
18 real 3.08s
19 user 0.48s
20 sys 0
21 swapped 0
22 total space 0
2. The Simplified Saaze installation is described in Simplified Saaze. It documents how to check for PHP version, check for yaml-parsing, FFI, MD4C extension, etc.
Once everything is installed, just run php saaze -mor.
2. Downloading all WordPress content #
We need a list or URLs available.
Below approach did not work: We use the month list in WordPress.
1for i in `seq 2018 2023`; do for j in `seq -w 01 12`; do curl https://www.publicomag.com/$i/$j/ > m$i-$j.html; done; done
Special cases for 2017 and 2024:
1curl https://www.publicomag.com/2017/10/ -o m2017-10.html
2curl https://www.publicomag.com/2017/11/ -o m2017-11.html
3curl https://www.publicomag.com/2017/12/ -o m2017-12.html
4...
5curl https://www.publicomag.com/2024/03/ -o m2024-03.html
It turned out that the month-lists lack links. To be exact: It lacks more than 466 URLs.
This approach fetches all links:
1$ curl https://www.publicomag.com/ -o wendt-p1.html
2$ time ( for i in `seq 2 124`; do
3 curl https://www.publicomag.com/page/$i/ -o wendt-p${i}.html;
4 done )
This creates 124 files:
1$ ls -alFt | head
2total 25580
3drwxr-xr-x 2 klm klm 4096 Apr 2 11:34 ./
4drwxr-xr-x 4 klm klm 4096 Apr 2 11:33 ../
5-rw-r--r-- 1 klm klm 208194 Apr 2 11:28 wendt-p1.html
6-rw-r--r-- 1 klm klm 187908 Apr 2 11:27 wendt-p124.html
7-rw-r--r-- 1 klm klm 203575 Apr 2 11:27 wendt-p123.html
8-rw-r--r-- 1 klm klm 206497 Apr 2 11:27 wendt-p122.html
9-rw-r--r-- 1 klm klm 207572 Apr 2 11:27 wendt-p121.html
10-rw-r--r-- 1 klm klm 207970 Apr 2 11:27 wendt-p120.html
11-rw-r--r-- 1 klm klm 206010 Apr 2 11:27 wendt-p119.html
12...
List of URLs:
1perl -ne 'print $1."\n" if /<h2 class="post-title"><a href="([^"]+)"/' wendt-p*.html > allURL
Downloading all posts uses below Perl script blogwendtcurl:
1#!/bin/perl -W
2# Download content from www.publicomag.com (Alexander Wendt) given a list of URLs
3# Elmar Klausmeier, 05-Mar-2024
4
5use strict;
6my $fn;
7my @F;
8
9while (<>) {
10 chomp;
11 @F = split('/');
12 $F[5] =~ s/a%cc%88/ä/;
13 $fn = $F[3] . '-' . $F[4] . '-' . $F[5] . '.html';
14 printf $fn . "\n";
15 `curl $_ -o $fn`;
16}
This creates a list of HTML files:
1$ ls -alFt | head
2total 175856
3drwxr-xr-x 3 klm klm 4096 Mar 7 19:16 ../
4drwxr-xr-x 2 klm klm 69632 Mar 5 19:53 ./
5-rw-r--r-- 1 klm klm 203580 Mar 5 19:53 2024-03-18471.html
6-rw-r--r-- 1 klm klm 252784 Mar 5 19:53 2024-03-wenn-die-zukunft-ans-fenster-des-gruenen-hauses-klopft.html
7-rw-r--r-- 1 klm klm 203765 Mar 5 19:53 2024-03-zeller-der-woche-niedere-gruende.html
8-rw-r--r-- 1 klm klm 203337 Mar 5 19:53 2024-02-zeller-der-woche-widerstaendler.html
9-rw-r--r-- 1 klm klm 231904 Mar 5 19:52 2024-02-das-nie-wieder-deutschland-und-seine-millionen-fuer-judenhasser.html
10...
3. Analyzing content types #
1. Fonts.
- Logo: Shadows Into Light Two, original uses image instead. Another contender could be Croissant One.
- Text: Playfair Display
2. Categories. Categories over all posts are as follows:
1$ perl -ne 'print $1."\n" if / hentry category-([-\w]+)/' *.html | sort | uniq -c | sort -rn
2 595 spreu-weizen
3 486 politik-gesellschaft
4 122 medien-kritik
5 28 fake-news
6 3 hausbesuch
7 1 film
Different, i.e., multiple, categories can be attributed to a single post. However, the majority of posts only has a single category attached.
In the above list there is no categoriy "alte-weise". I added this category.
We want to convert images in "Alte-Weise" to text. That way loading those pages should be way quicker.
Therefore we need to download those images and convert them with tesseract.
3. URLs. Below Perl one-liners produces a list of URLs for the images.
1perl -ne 'print "$1$2\n" if (/^<meta property="og:image"\s+content="(https:\/\/www\.publicomag\.com\/wp-content\/uploads\/\d+\/\d+\/)(Alte-Weis[^"]+|AlteWeise[^"]+|AlteuWeise[^"]+|auw-[^" ]+|aub_[^"]+|auw_[^"]+|AuW_[^"]+|AW_[^"]+|OW[^"]+)"/)' *.html | sort > ../allAlte-WeiseURL
Downloading these images:
1perl -ane 'chomp; @F=split(/\//); `curl $_ -o $F[7]`' ../allAlte-WeiseURL
2curl https://www.publicomag.com/wp-content/uploads/2023/01/Alte-Weise_C.Wright-Mills-1011x715.jpg -o Alte-Weise_Wright_Mills-scaled.jpg
4. JavaScript. A huge number of JavaScript libraries are loaded. We will get rid of them all.
- Google Analytics
- JQuery Minimal
- JQuery Migrate
- WordPress User Avatar
- Buzzblog Hercules Likes
- Borlabs Cookies Prioritize
- WordPress GDPR Compliance
- Comment Reply
- Contact Form
- JQuery Easing for Buzzblog
- JQuery MagnificPopup for Buzzblog
- JQuery Plugins for Buzzblog
- JQuery JustifiedGallery for Buzzblog
- Buzzblog Bootstrap
- Owl Carussel for Buzzblog
- Buzzblog AnimatedHeader
- Shariff
- MailPoet
- Akismet
- Borlabs Cookies Minimal
4. Reducing number of images #
An easy target is the logo: this was replaced with plain text. This saves one roundtrip to the web-server.
1. For the category "alte-weise" the entire image with text is converted to two elements:
- An image
- The actual text
The image is scanned with tesseract.
That way the text can be searched via Pagefind. Also, the required bandwidth is reduced.
Old:

New:

The new approach is to use a blockquote, where the CSS puts an image on top:
1blockquote blockquote {
2 background: transparent no-repeat top/30% url('/img/Alte-Weise-Kopf.svg');
3 text-align:center;
4 padding-left:2rem;
5 padding-right:2rem;
6 padding-top:12rem;
7 padding-bottom:1rem;
8 background-color:#b6c7c8; border-radius:2.5rem
9}
The actual text in Markdown is then:
1>> „Zweifel ist nicht das Gegenteil, sondern ein Element des Glaubens.“
2>>
3>> Paul Tillich
That way the ordinary blockquote in Markdown (single >) is left free to be used for citations.
Obviously, entering the text in >> is way easier than producing an image for each epigram.
2. Care was taken to reduce the number of images needed for the social media icons.
Old:

New:

That reduces loading eight images. However, you need to load some font glyphs.
1<a style="background-color:SkyBlue; color:white" href="https://telegram.me/share/url?url=<?=$urlEncoded?>&text=<?=$titleEncoded?>"
2 title="Teilen auf Telegram" target=_blank> <span class=symbols>🮰</span> Telegram </a>
In particular this symbol U+1fbb0 is %F0%9F%AE%B0 when URL encoded:
1@import url('https://fonts.googleapis.com/css2?family=Noto+Sans+Symbols+2&text=%F0%9F%97%8F%F0%9F%AE%B0%F0%9F%96%82%F0%9F%96%A8');
Similarly, symbol U+1f5cf is %F0%9F%97%8F when URL encoded.
5. Converting WordPress HTML to Markdown #
Perl script blogwendtmd is used to convert a single HTML file to Markdown.
1$ time ( for i in *.html; do blogwendtmd $i; done )
2 real 94.95s
3 user 136.51s
4 sys 0
5 swapped 0
6 total space 0
The long runtime is exclusively for running tesseract, i.e., the conversion from image to text.
Once all WordPress posts are converted to Markdown, this script no longer needs to be run, obviously.
blogwendtmd is 180 lines of Perl code.
Listing of all authors and their corresponding directories.
1$ perl -ne 'print $1."\n" if /\/author\/([^\/]+)\//' 2*.html | sort -u
2alexander
3archi-bechlenberg
4bernd-zeller
5cora-stephan
6david-berger
7hansjoerg-mueller
8joerg-friedrich
9matthias-matussek
10redaktion
11samuel-horn
12wolfram-ackner
Each of these authors have a separate index beneath /author/.
Generating all yearly overviews:
1for i in *; do ( echo $i; cd $i; blogwendtdate -gy$i *.md > index.md ) done
Perl script blogwendtdate generates a Markdown file, which contains all articles for the corresponding year.
This script first has to store all posts for one year in a hash, sort it according to date in the frontmatter.
1my @L; # list of posts in a year, in the beginning not necessarily sorted
2
3sub markdownfile(@) {
4 my $f = $_[0];
5 my ($flag,$title,$date,$draft) = (0,"","",0);
6 open(F,"<$f") || die("Cannot open $f");
7 while (<F>) {
8 if (/^\-\-\-\s*$/) {
9 last if (++$flag >= 2);
10 . . .
11 }
12 if ($draft == 0 && length($title) > 0 && length($date) > 0) {
13 push(@L, sprintf("%s: [%s](%s%s)",$date,$title,$prefix,substr($f,0,-3)) );
14 }
15 close(F) || die("Cannot close $f");
16}
17
18while (<@ARGV>) {
19 #printf("ARGV=|%s|\n",$_);
20 next if (substr($_,-8) eq "index.md");
21 markdownfile($_);
22}
23
24for (sort @L) {
25 printf("%d. %s\n",++$cnt,$_);
26}
Many HTML errors were corrected, which were reported by Nu Html Checker. See for example das-magische-sprechen-schafft-macht-fuer-den-augenblick.
6. Handling comments #
The Publico blog contains comments, where readers have left their thoughts.
In Perl script blogwendtmd we detect comments by checking for <h5> tags for the beginning, and pinglist for the end of all comments.
1if (/^<ul class="pinglist">/) { $flag = 0; next; }
2elsif (/<h5 class="comments-h">/) {
3 ...
4 $flag = 1;
5}
6next if ($flag == 0);
We refrained from integrating the commenting system HashOver. It is not difficult, as we have already demonstrated in the Lemire theme. However, for a political blog a comment system is rather "dangerous", as it can attract rather unwelcoming writings. Under German law the hoster of these comments becomes liable. Essentially, you therefore must check every comment manually:
... da die Kommentare alle gesichtet werden müssen und die Redaktion nach wie vor aus dem Gründer Alexander Wendt und einer Teilzeitredakteurin besteht, können sie nicht umgehend online gehen.
In light of the high volume of comments HashOver should most probably be added.
7. Running static site generator #
In serial mode it takes less than 3 seconds to build 19 collections without comments.
With comments it takes less than 6 seconds to process 23 thousand pages, see below.
This build time can be almost halved by using parallelisation with -p16.
1$ time php saaze -morb /tmp/build
2Building static site in /tmp/build...
3 execute(): filePath=./content/alexander.yml, nSIentries=770, totalPages=39, entries_per_page=20
4 execute(): filePath=./content/alte-weise.yml, nSIentries=131, totalPages=7, entries_per_page=20
5 execute(): filePath=./content/archi-bechlenberg.yml, nSIentries=5, totalPages=1, entries_per_page=20
6 execute(): filePath=./content/bernd-zeller.yml, nSIentries=332, totalPages=17, entries_per_page=20
7 execute(): filePath=./content/cora-stephan.yml, nSIentries=1, totalPages=1, entries_per_page=20
8 execute(): filePath=./content/david-berger.yml, nSIentries=1, totalPages=1, entries_per_page=20
9 execute(): filePath=./content/fake-news.yml, nSIentries=28, totalPages=2, entries_per_page=20
10 execute(): filePath=./content/film.yml, nSIentries=1, totalPages=1, entries_per_page=20
11 execute(): filePath=./content/hansjoerg-mueller.yml, nSIentries=2, totalPages=1, entries_per_page=20
12 execute(): filePath=./content/hausbesuch.yml, nSIentries=2, totalPages=1, entries_per_page=20
13 execute(): filePath=./content/joerg-friedrich.yml, nSIentries=2, totalPages=1, entries_per_page=20
14 execute(): filePath=./content/mag.yml, nSIentries=1235, totalPages=62, entries_per_page=20
15 execute(): filePath=./content/matthias-matussek.yml, nSIentries=1, totalPages=1, entries_per_page=20
16 execute(): filePath=./content/medien-kritik.yml, nSIentries=123, totalPages=7, entries_per_page=20
17 execute(): filePath=./content/politik-gesellschaft.yml, nSIentries=486, totalPages=25, entries_per_page=20
18 execute(): filePath=./content/redaktion.yml, nSIentries=112, totalPages=6, entries_per_page=20
19 execute(): filePath=./content/samuel-horn.yml, nSIentries=3, totalPages=1, entries_per_page=20
20 execute(): filePath=./content/spreu-weizen.yml, nSIentries=596, totalPages=30, entries_per_page=20
21 execute(): filePath=./content/wolfram-ackner.yml, nSIentries=6, totalPages=1, entries_per_page=20
22Finished creating 19 collections, 19 with index, and 1248 entries (2.58 secs / 809.47MB)
23#collections=19, parseEntry=0.7290/23712-19, md2html=1.1983, toHtml=1.2839/23712, renderEntry=0.1562/1248, renderCollection=0.0403/224, content=23712/0
24 real 5.16s
25 user 4.36s
26 sys 0
27 swapped 0
28 total space 0
Running pagefind, i.e., indexing al keywords for the WebAssembly based search functionality:
1$ time pagefind -s . --exclude-selectors aside --exclude-selectors footer --force-language=de
2
3Running Pagefind v1.0.4
4Running from: "/tmp/buildwendt"
5Source: ""
6Output: "pagefind"
7
8[Walking source directory]
9Found 1473 files matching **/*.{html}
10
11[Parsing files]
12Did not find a data-pagefind-body element on the site.
13↳ Indexing all <body> elements on the site.
14
15[Reading languages]
16Discovered 1 language: de
17
18[Building search indexes]
19Total:
20 Indexed 1 language
21 Indexed 1473 pages
22 Indexed 133261 words
23 Indexed 0 filters
24 Indexed 0 sorts
25
26Finished in 19.644 seconds
27 real 19.87s
28 user 18.28s
29 sys 0
30 swapped 0
31 total space 0
It would take 11 seconds without comments, i.e., indexing 77168 words.
8. Collections #
There are quite a number of collections at play in this theme.
The most important one being mag (short for magazine).
This directory contains all the blog posts.
All the other collections are just symbolic links to mag, i.e., they do not contain additional content.
1total 96
2drwxr-xr-x 4 klm klm 4096 Apr 27 17:11 ./
3drwxr-xr-x 7 klm klm 4096 May 13 13:00 ../
4lrwxrwxrwx 1 klm klm 3 Mar 26 21:48 alexander -> mag/
5-rw-r--r-- 1 klm klm 273 Apr 2 18:56 alexander.yml
6lrwxrwxrwx 1 klm klm 3 Apr 27 17:11 alte-weise -> mag/
7-rw-r--r-- 1 klm klm 225 Apr 27 17:10 alte-weise.yml
8lrwxrwxrwx 1 klm klm 3 Mar 31 17:22 archi-bechlenberg -> mag/
9-rw-r--r-- 1 klm klm 495 Apr 2 18:58 archi-bechlenberg.yml
10lrwxrwxrwx 1 klm klm 3 Mar 31 17:17 bernd-zeller -> mag/
11-rw-r--r-- 1 klm klm 213 Apr 2 18:01 bernd-zeller.yml
12lrwxrwxrwx 1 klm klm 3 Apr 2 15:18 cora-stephan -> mag/
13-rw-r--r-- 1 klm klm 707 Apr 2 19:01 cora-stephan.yml
14lrwxrwxrwx 1 klm klm 3 Apr 2 15:17 david-berger -> mag/
15-rw-r--r-- 1 klm klm 761 Apr 2 19:06 david-berger.yml
16drwxr-xr-x 2 klm klm 4096 Apr 2 16:24 error/
17-rw-r--r-- 1 klm klm 88 Apr 2 16:21 error.not_used_yml
18lrwxrwxrwx 1 klm klm 3 Apr 2 19:25 fake-news -> mag/
19-rw-r--r-- 1 klm klm 216 Apr 2 19:42 fake-news.yml
20lrwxrwxrwx 1 klm klm 3 Apr 2 19:25 film -> mag/
21-rw-r--r-- 1 klm klm 201 Apr 2 19:43 film.yml
22lrwxrwxrwx 1 klm klm 3 Mar 31 17:22 hansjoerg-mueller -> mag/
23-rw-r--r-- 1 klm klm 318 Apr 2 18:56 hansjoerg-mueller.yml
24lrwxrwxrwx 1 klm klm 3 Apr 2 19:25 hausbesuch -> mag/
25-rw-r--r-- 1 klm klm 219 Apr 2 19:42 hausbesuch.yml
26lrwxrwxrwx 1 klm klm 3 Apr 2 15:18 joerg-friedrich -> mag/
27-rw-r--r-- 1 klm klm 222 Apr 2 18:01 joerg-friedrich.yml
28drwxr-xr-x 10 klm klm 4096 May 12 20:56 mag/
29-rw-r--r-- 1 klm klm 110 Apr 1 22:25 mag.yml
30lrwxrwxrwx 1 klm klm 3 Mar 31 17:22 matthias-matussek -> mag/
31-rw-r--r-- 1 klm klm 228 Apr 2 18:02 matthias-matussek.yml
32lrwxrwxrwx 1 klm klm 3 Apr 2 19:25 medien-kritik -> mag/
33-rw-r--r-- 1 klm klm 234 Apr 2 19:27 medien-kritik.yml
34lrwxrwxrwx 1 klm klm 3 Apr 2 17:47 politik-gesellschaft -> mag/
35-rw-r--r-- 1 klm klm 255 Apr 2 17:59 politik-gesellschaft.yml
36lrwxrwxrwx 1 klm klm 3 Mar 31 17:16 redaktion -> mag/
37-rw-r--r-- 1 klm klm 202 Apr 2 18:03 redaktion.yml
38lrwxrwxrwx 1 klm klm 3 Mar 31 17:21 samuel-horn -> mag/
39-rw-r--r-- 1 klm klm 259 Apr 2 19:03 samuel-horn.yml
40lrwxrwxrwx 1 klm klm 3 Apr 2 19:25 spreu-weizen -> mag/
41-rw-r--r-- 1 klm klm 231 Apr 2 19:27 spreu-weizen.yml
42lrwxrwxrwx 1 klm klm 3 Mar 31 17:22 wolfram-ackner -> mag/
43-rw-r--r-- 1 klm klm 542 Apr 2 19:05 wolfram-ackner.yml
The collection yaml files look like this. First mag.yml:
1title: Publico
2sort_field: date
3sort_direction: desc
4index_route: /
5entry_route: /{slug}
6more: true
7rss: true
Now alexander.yml, which filters for author:
1title: Publico - Autor Alexander Wendt
2subtitle: "Alexander Wendt ist Herausgeber von Publico."
3sort_field: date
4sort_direction: desc
5index_route: /author/alexander
6entry: false
7entry_route: /{slug}
8more: true
9filter: return ($entry->data['author'] === 'Alexander Wendt');
Similarly, alte-weise.yml, which filters for categories:
1title: Publico - Alte & Weise
2sort_field: date
3sort_direction: desc
4index_route: /alte-weise
5entry: false
6entry_route: /{slug}
7more: true
8filter: return (array_search('alte-weise',$entry->data['categories']) !== false);
Except mag.yml, all other yaml files set rss: false.
9. Templates #
This theme uses the following PHP template files:
bottom-layout.php: commonalities for the bottom partentry.php: template for the entry, i.e., the usual blog posterror.php: 404 page, or other error conditionshead.php: HTML for the first few lines for all HTML filesindex.php: template for the index, i.e., the listing of postsoverview.php: HTML sitemaprss.php: RSS feedsitemap.php: XML sitemaptop-layout.php: commonalities for the top part
I use the following hierarchy of PHP files for my entry-template, i.e., the template for a blog post:
[markmap]
entry.php #
top-layout.php #
head.php #
Actual content: $entry['content'] #
bottom-layout.php #
[/markmap]
The following hierarchy is used for the index-template, i.e., the template for showing a reverse-date sorted list of blog posts:
[markmap]
index.php #
top-layout.php #
head.php #
for-loop over entry-excerpts #
bottom-layout.php #
[/markmap]